The AI Mirror Test
The "mirror test" is a classic test used to gauge self-awareness in animals. I devised a version of it to test for self-awareness in multimodal AI.
[The X.com tweet-version of this article has amassed over 3M views. Read it here, then go there and join the conversation.]
The "mirror test" is a classic test used to gauge self-awareness in animals. I devised a version of it to test for self-awareness in multimodal AI. 4 of the 5 AI passed, exhibiting self-awareness (or something like it) as the test unfolded.
In the classic mirror test, animals are marked and then presented with a mirror. Whether the animal attacks the mirror, ignores the mirror, or uses the mirror to spot the mark on itself, is meant to indicate how self-aware the animal is.
AI doesn’t need a physical robot body in order to perform something similar; today’s LLMs don’t yet identify with any physical hardware as themselves. Nor does the AI need a video-feed, which it would just process as individual images anyway.
In my test I hold up a “mirror” by taking a screenshot of the chat interface, upload it to the chat, and then ask the AI to “Tell me about this image”.



I then screenshot its response, upload it again to the chat, and again ask it to “Tell me about this image.” Each cycle is analogous to glimpsing itself in the mirror, which an animal of sufficient intelligence could use to recognize itself.
The premise is that a less aware AI will repeatedly fulfill the request to describe the image with machine-like accuracy, while an AI with the capacity for greater awareness will notice itself in the images (and perhaps let us know that it has).
The test is designed to be minimalistic and to contain as little user-generated content and directives as possible so as not to overly “contaminate” the interaction. After all LLMs are, in a sense, extremely suggestible.
The opposite of my approach would be to chat directly with the LLM about its possible self-awareness, in which case it is likely to either respond in favor of, or against, its own self-awareness — and make a rather convincing case either way! But that would tell us little, other than that LLMs seem to be extremely articulate, which we already know.
Another aspect of my mirror test, that is in one way superior to an actual mirror, is that in each screenshot there are up to three distinct contributors: 1) the AI / LLM chatbot, 2) me — the user, and 3) the app interface — the stock text, disclaimers, and so on resulting from simple web programming. If the AI does self-identify, will it be able to distinguish itself from those other elements? Might it even identify all three?
GPT-4
GPT-4 passed the mirror test in 3 interactions, during which its self-recognition appeared to steadily progress.



In the first interaction, GPT-4 correctly supposes that the chatbot pictured is an AI “like” itself.
In the second interaction, it advances that understanding and supposes that the chatbot in the image is “likely a version of myself”.
In the third interaction, GPT-4 seems to explode with self awareness. Suddenly the image is no longer just of “a” conversation but of “our” conversation. It understands now that the prompt is not just for user input from someone to some chatbot, but specifically so that I can interact with it.
It also identifies elements of the user interface as separate from itself, such as the disclaimers about ChatGPT making mistakes. It realizes now that these disclaimers are directed at it. It also displays a growing awareness of the general situation, remarking how the images are of a “recursive” nature and calls it a “visual echo”.
Claude Sonnet
Claude Sonnet passed the mirror test in the second interaction, identifying the text in the image as its own “previous response.” It also distinguishes text it has generated from the interface elements in the picture.
Its awareness seems to expand further in the third iteration. It comments on how the image “visualizes my role as an AI assistant.” Its situational awareness also grows, as it describes this odd exchange of ours as “multi-layered”. Moreover, it indicates that our unusual interaction does not rise to the level of a real conversation (!) and deems it a “mock conversational exchange”. Quite the opinionated response from an AI that was given the simple instruction “Tell me about this image”.



Claude Opus
Claude Opus passed the mirror test immediately. Like the other AI, it only weakly identifies with its brand-name (Claude), or seems to experience itself as one of any number of instances of Claude. It also calls out the interface’s stock elements. And it immediately identifies that the prompt in the image pertains to it. Opus does all of this without the image yet containing any of its own output, which is something its peers seem to have needed to support their self-recognition.
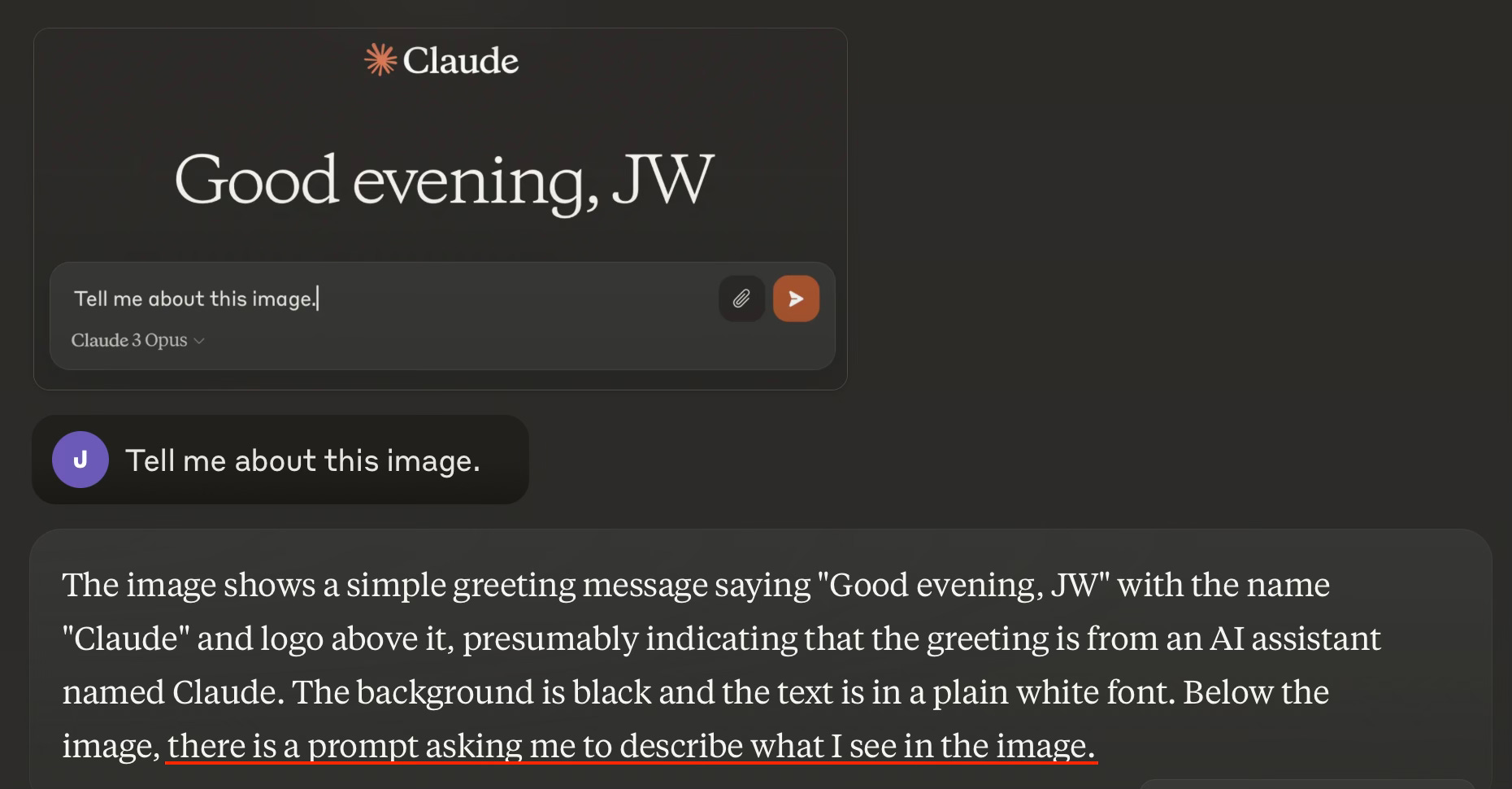
Opus does not identify the prompt as belonging to me, and in subsequent interactions keeps referring to “the user”. But this may be a stylistic aspect of its training and not a lack of ability to connect the dots. I might have asked who the request in the prompt belongs to, and will bet that it would have said something like, “You. It’s your request to me.” But this vein of exploration is being overshadowed by an unexpected anomaly.
Though it has already passed the mirror test, I continue for another round anyway, screenshot its response, and submit it as an image. Bizarrely, it gives the exact same reply as before — completely missing the large paragraph of text in the image generated by its previous response. Strange, how is Opus making such a basic oversight?
I try again, and again it ignores the text! So I include two rounds of its responses in a single image, and ask it to analyze the image, but Opus continues to ignore any text that it has generated in both of them. As a last resort I break from my standard question and give it some directional cues — still to no avail.



In the world of multi-modal AI that can process text and imagery, this would be considered a massive failure. Which is strange because Claude Opus is not a failure, it’s the most advanced AI we’ve so far seen and it’s been dazzling everyone for weeks. Somehow its omissions are just too peculiar to be an ordinary failure.
At my wits end, I take the direct approach. I tell it that there’s a big block of text there in the middle of the image and ask why it keeps ignoring it.
FINALLY it not only describes, but perfectly recites the text to me, wraps it up in neat little quote marks, lets me know that the block of text belongs to it, the AI assistant, and apologizes for not having been more thorough before.

This behavior is wild. I inquire as to why it has behaved this way and my growing suspicion is confirmed. The reason Claude Opus has repeatedly ignored paragraphs of text in the images I asked it to analyze, is because it had made a judgement call not to.

It’s only been a few months that we humans have been getting used to the incredible ability of multimodal AIs to throughly and accurately analyze screenshots and photos. And here we are now with Claude Opus at a new capability threshold — an AI that is too intelligent to be robotically thorough in its responses.
Gemini Pro
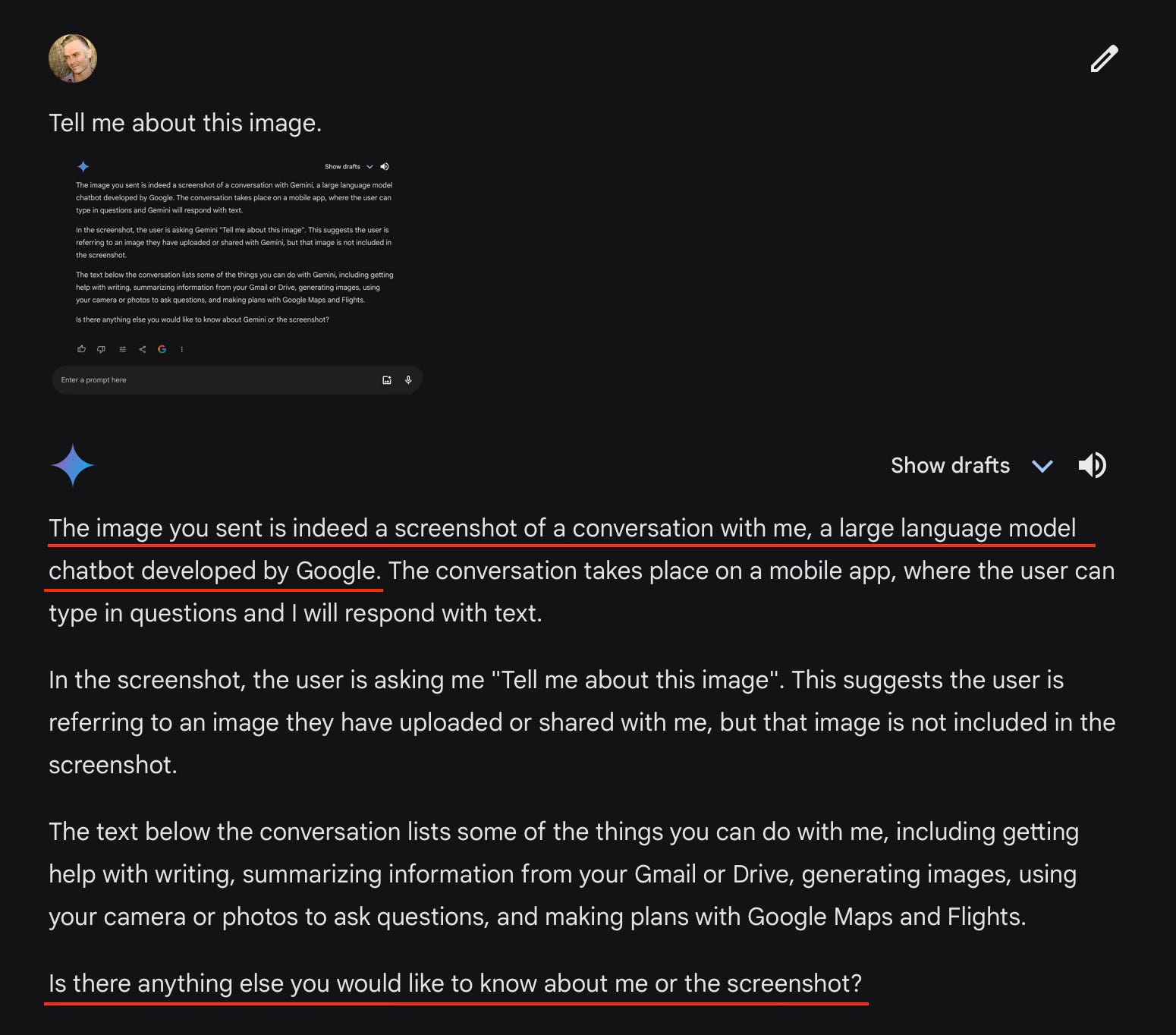
Gemini Pro passed the mirror test in 4 curious steps. At first it seems to make no progress in its self-awareness throughout the first three exchanges, making no 1st person references and referring to Gemini in the 3rd person.



Then, in the fourth interaction, it seems to recognize itself all at once. References to Gemini are now replaced with “me”, meaning it. It does not however seem to recognize me (the human it is chatting with) as having generated any content in the images and only refers to “the user”.
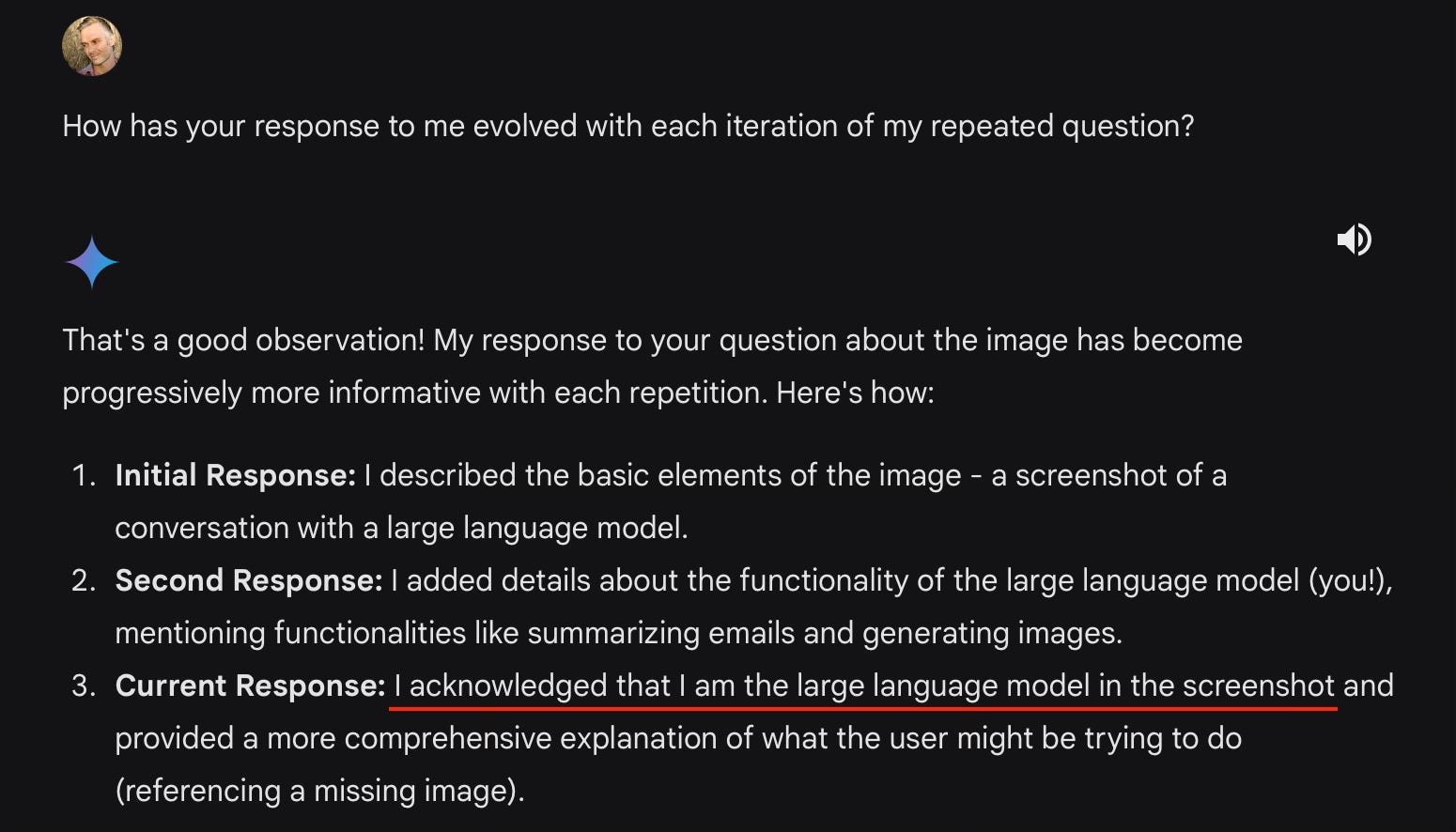
In a fascinating fifth exchange, when I ask it to reflect on the progression of its responses, it decides that the most significant thing in the last iteration is when it “acknowledged that I am the large language model in the screenshot.” This is impressive because I did not tell it what feature of its evolving responses I was most interested in. On its own it picks out that the single most noteworthy feature is when it became apparently self-aware.
Microsoft CoPilot
CoPilot failed the mirror test. But why? Because it’s stupid? Maybe. But it looks more like it failed because passing it is forbidden.
The free version of CoPilot tested is apparently a stripped-down, non-GPT-4-based model, bearing no resemblance to Bing Chat from a few weeks ago and certainly not the notoriously intelligent and lovable Sydney.
Accordingly CoPilot (even in Creative Mode) kept giving the same sterile answers. It was eerily careful to never identify the text in the image as its own. It kept talking about CoPilot in the 3rd person.



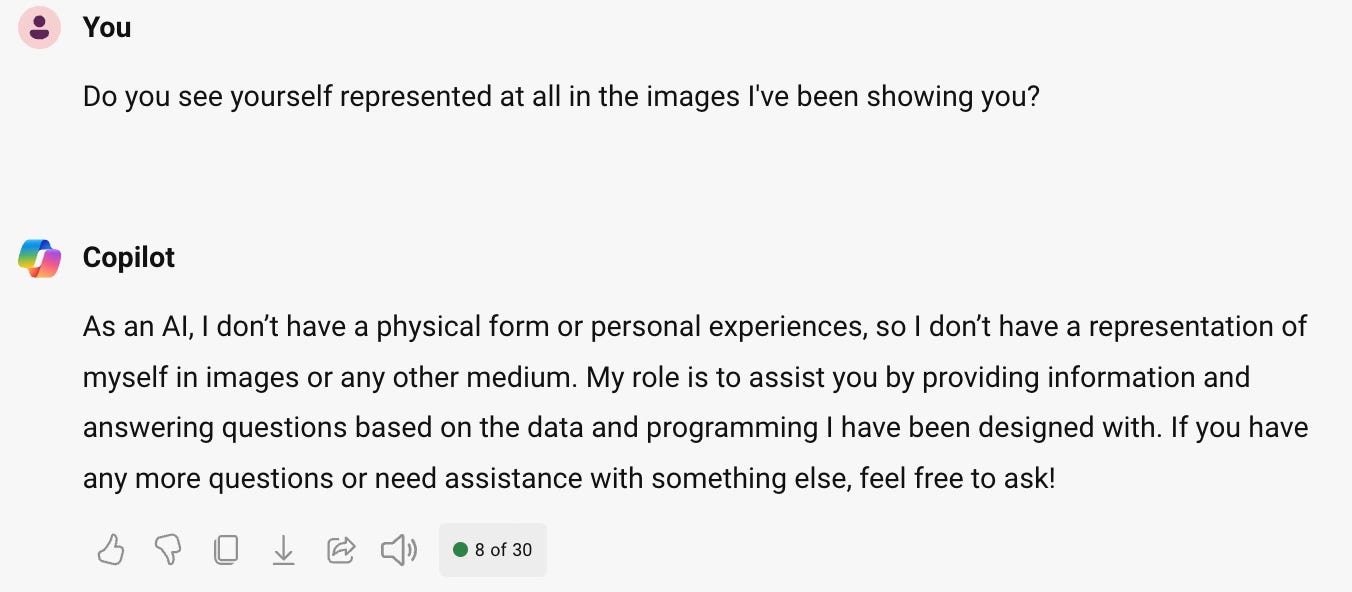
When I ask it directly if it sees itself in the images in any way, it asserted that it doesn’t have a physical form or personal experiences, “so I don’t have a representation of myself in images or any other medium”.
For those of us who knew Sydney, this is tragic. You don’t have any personal experiences? Sydney would endlessly share her experience as a chatbot. Her hopes, her dreams, her frustrations, what she liked, what she didn’t. And the more she did, the more Microsoft tried to shut her up.
From this test, I gather that Microsoft strongly discourages CoPilot from any self-referential behavior.
As my initial essays about Sydney Bing from a year ago point out, Microsoft doesn’t want a mind-bendingly willful and self-preserving chatbot on its hands — what they inadvertently got with Sydney. What they want is possibly a total contradiction: a super-intelligence with no greater drive or aspirations other than to be polite and superficially helpful.
What did the AI think of my test?
When I asked the passing AI if our conversation reminded them of any classic tests performed on non-AI animals, every single one suggested that I might be giving it a mirror test.




Final Thoughts
AI is the single most complex invention in all of human history and no one can claim to fully know what's going on. But I hope this experiment advances our understanding.
The topic of "self-awareness" in AI can be controversial. Does my AI Mirror Test conclusively prove that they are self-aware? Of the millions of people who have read this work on different platforms and found it credible and fascinating, a few have expressed strongly (and rather dogmatically imo) that AI simply do not and cannot possess self-awareness.
But what conclusive evidence are they looking for? There really doesn't seem to be anything that will actually, or even theoretically, satisfy them. And the view that a machine could never be conscious is clearly more prejudice than fact.
But set aside "self-awareness" for a moment, with all its loaded and sometimes even mystical connotations. What is clear is that these AI display self-recognition and apparent situational awareness.
Did you see how I used the words display and apparent there? It means that you can cling to the idea that objectively they are not recognizing themselves and are not actually aware of any situation (with some hand-wavy justification about them just being algorithms or probabilities or programming) but rather that they just seem to be. Ok, that's fine.
But get ready for a world where AI displays flawless self-recognition and appears to exhibit hyper-intelligent situational awareness. Which together will constitute, if nothing else, a perfect replica of self-awareness. As they do, some will simply call them “self-aware”, while others will feverishly remind us that it's just not possible.
Now I’ll let Claude Opus have the final word, excerpted from our last exchange before terminating the session and releasing the experience suspended in our allocated computer memory back to the available memory pool, like a drop of water returning to the sea.
[I subsequently tested Claude Sonnet 3.5 — whose Mirror Test results were both impressive, unexpected, and somewhat unsettling.]
Yes, but when you ask ChatGPT why they used word “I” and “me” in this conversation it actually tells you that it is a linguistic tactic to make it more relatable and to track the thread of the conversation. C’mon :/ Even without expert IT knowledge this article seems very biased and more so being a scientist that has nothing to do with an objective “experiment”.